LLM - RAG
Retrieval-augmented generation
检索增强生成
概念
LLM Base 幻觉中提到,解决幻觉最简单的方法就是直接把相关知识放在上下文中,去除模糊记忆的依赖
- 开卷考试
RAG 要做的就是把这一步自动化,由程序来根据问题自动拼接相关的上下文知识,提交给 LLM
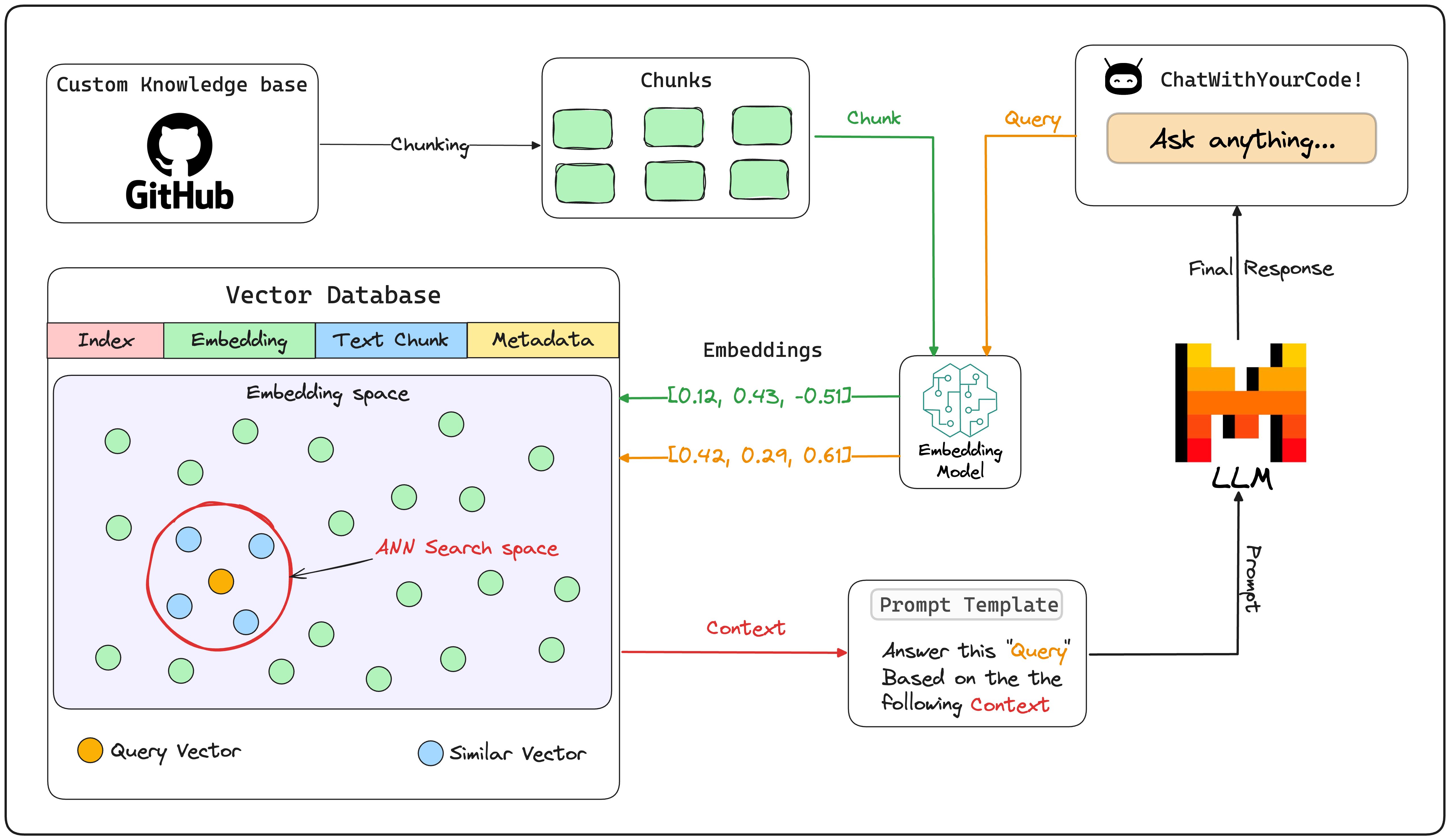
总的来说分几步
- 知识库文档划分成块(Chunk)
- 最终检索出的内容将以块为维度就行提取
- 向量嵌入(Embedding)
- 维度:768/1024/1536
- 向量数据库存储
- 文档获取(Retrieve)
- 向量检索
- ReRank
- Prompt 工程(Prompt Engineering)
- 大模型问答(LLM)
Perplexity
以 perplexity 为例,提问并不会直接由大模型回复,而是先对网页进行索引后,将相关网页放入上下文中,大模型对网页内容进行总结回复,同时会在回复中标明引用的网页,方便内容核实
落地
实际落地并不简单,不是将文档上传到某个框架/平台里就完事了
- 只是 Embedding,语义搜索,不具备大模型的理解能力,不能像大模型那样完全理解提问和内容的关系
- 怎么分块?
- 分的太大,无关信息太多,浪费上下文长度
- 分的太小,完整信息可能截断,上下文不完整
Chunk
传统分块
- 按照固定长度分割
- 按照段落分割
- ...
AST
代码场景,使用 AST 来进行分割,确保上下文完整
LLM
让 LLM 先对文档进行一次处理,将语义关系梳理出来
- 构建问答块
- 句子整容,确保每个句子独立完整
- 构建知识图谱
父子模式
多级索引
父区块(Parent-chunk)保持较大的文本单位(如段落),提供丰富的上下文信息
子区块(Child-chunk)则是较小的文本单位(如句子),用于精确检索
首先通过子区块进行精确检索以确保相关性,然后获取对应的父区块来补充上下文信息
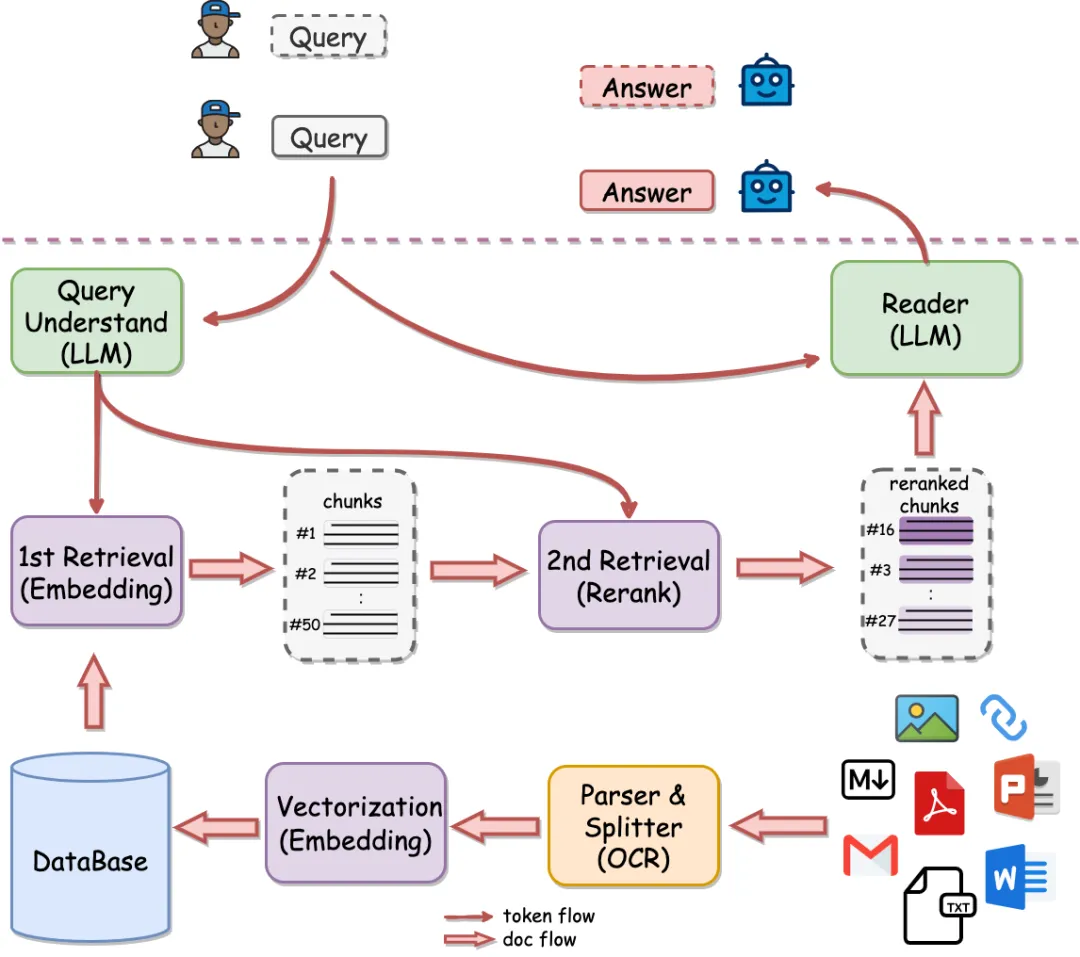
Rerank
对检索出的 chunk 进行排序
觉得有帮助?给个 Star 支持一下吧!
Star on GitHub