终端的异步状态管理
标题经历了三次变化
- 前端的服务端状态管理
- 不仅是服务端状态?
- 前端的异步状态管理
- 不仅是前端?
- 终端的异步状态管理
- 或者可以称为
*UI?
- 或者可以称为
TL;DR
开发与用户进行交互的界面或工具时,面对异步状态需要等、慢、数据过时这些不可避免的事实下,怎么尽可能的提高 UX
具体到前端
- 为什么要使用异步状态管理库
TanStack Query/SWR/RTK Query,它们与同步状态管理redux/jotai/zustand有什么区别 - 使用
redux-thunk实现一个异步状态管理(React Query API)
TanStack Query(FKA React Query)
前端?终端?
同步、异步
同步代码
代码立即执行并完成,不需要等待其他任何操作
a = 0
printf(a)
a = 1
printf(a)异步代码
需要 等待 某些操作的完成:锁、文件、网络 IO 等等
read(fd, buffer, BUFFER_SIZE)聚焦到前端最常见、常用的就是 fetch -- 网络请求,所以就前端来说 异步状态 ≈ 服务端状态
当然还有诸如
IndexedDB、Web Worker以及各种授权请求(蓝牙、摄像头、地理位置)等等,本质是一样的
同理,同步状态 ≈ 客户端状态
差异

从四个方面去看:
- 存储位置
- 访问速度
- 访问/修改权
- 有效性
同步

- 存储位置:在内存中,非持久化
- 访问速度:即时访问、修改
- 访问/修改权:私有的,当前线程可以访问、修改
- 有效性:修改后可以稳定同步更新至最新状态
异步

- 存储位置:在外部(远端,eg: DB),多数是持久化
- 访问速度:慢、有时延,异步访问、修改
- 访问/修改权:共享所有权,可能被其他人修改
- 有效性:持有的只是快照,状态可能过时
终端的异步状态
所有程序员都会关心异步的写法(async/await)和组织(rxjs),但也许只有 end device 会(必须)去关心异步耗时、状态更新这些事情

因为我们已经是链路的终点了,我们不关心,那就只能用户去关心,用户会去关心吗?(≈ 用户流失)
异步 == 等待 == 慢 == 体验不好
核心问题:用户体验
主题:在异步需要等、慢、数据过时这些不可避免的事实下,怎么尽可能的提高 UX
异步状态的挑战

要想提高异步的体验(UX、DX),我们大概要面对如下挑战:
- 缓存(可能是编程中最难做的事情)
- 内存管理和垃圾收集
- 尽快反映数据更新
- 请求状态管理
- 丢弃/取消请求
- 多组件请求合并
- 性能优化
- 用户体验
- 乐观更新
- 渲染优化
- ...
本地、全局
开始之前有一点要明确
TIP
异步状态应该是本地的还是全局的?
是应该这样?
const [state, setState] = useState()
useEffect(() => {
fetch(API.list).then((data) => setState(data))
}, [])还是这样?
const state = useSelector(listSelector)
useEffect(() => {
dispatch(getList)
}, [])前端视角
听到过的回答:
如果这个状态只有组件自己用的就放本地,如果大家都用的就放全局
这个回答是经不起推敲的,产品是在不断迭代的,我们的判断仅限于当下这个时刻而已
V1: 自己 -- 放在本地
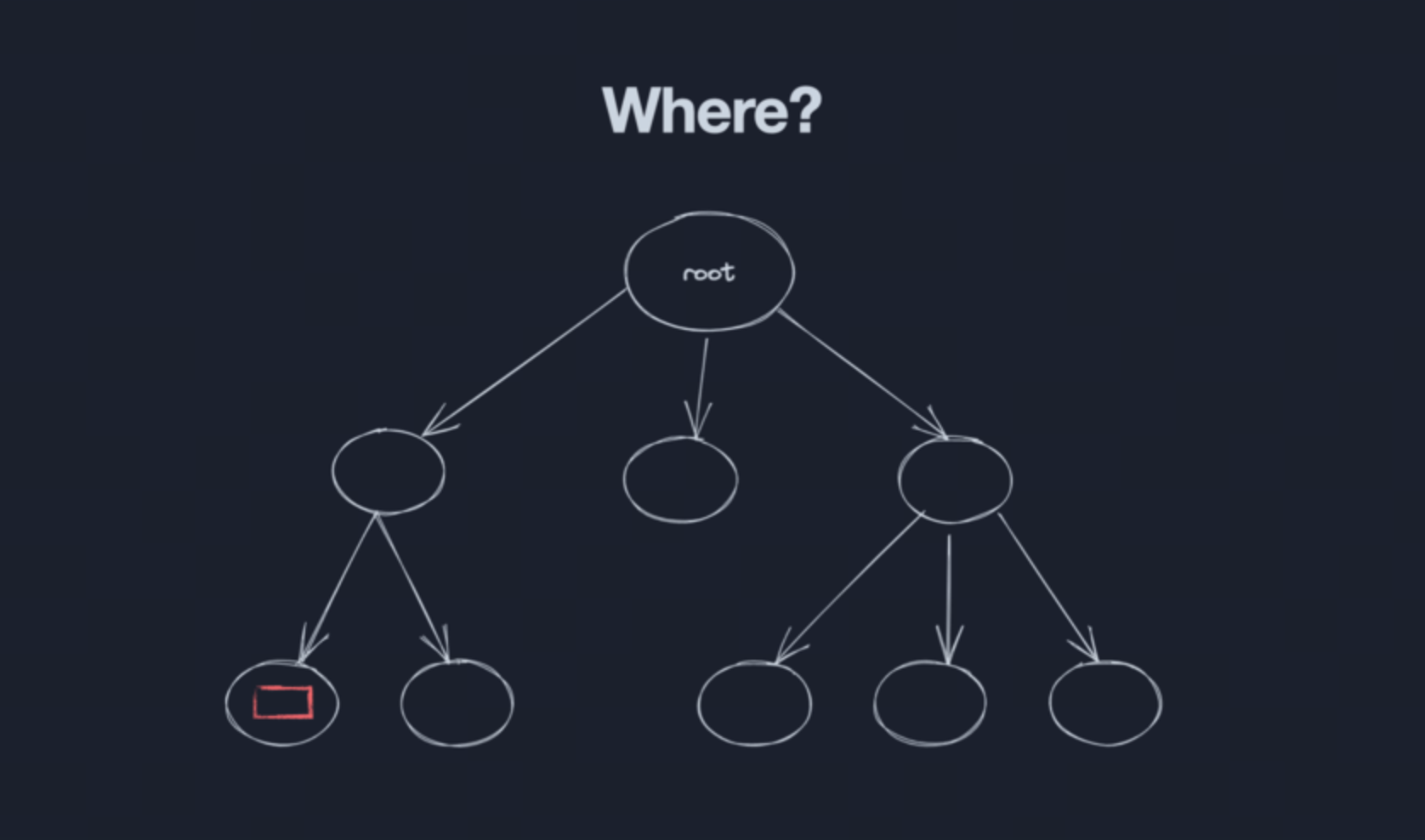
V2: 兄弟节点 -- 提升到父级
V3:跨节点 -- 提升到全局(root)
V4:需求全砍了,变回 V1 版本了 -- 再降下来?
单从开发维护角度来看,应该是全局的
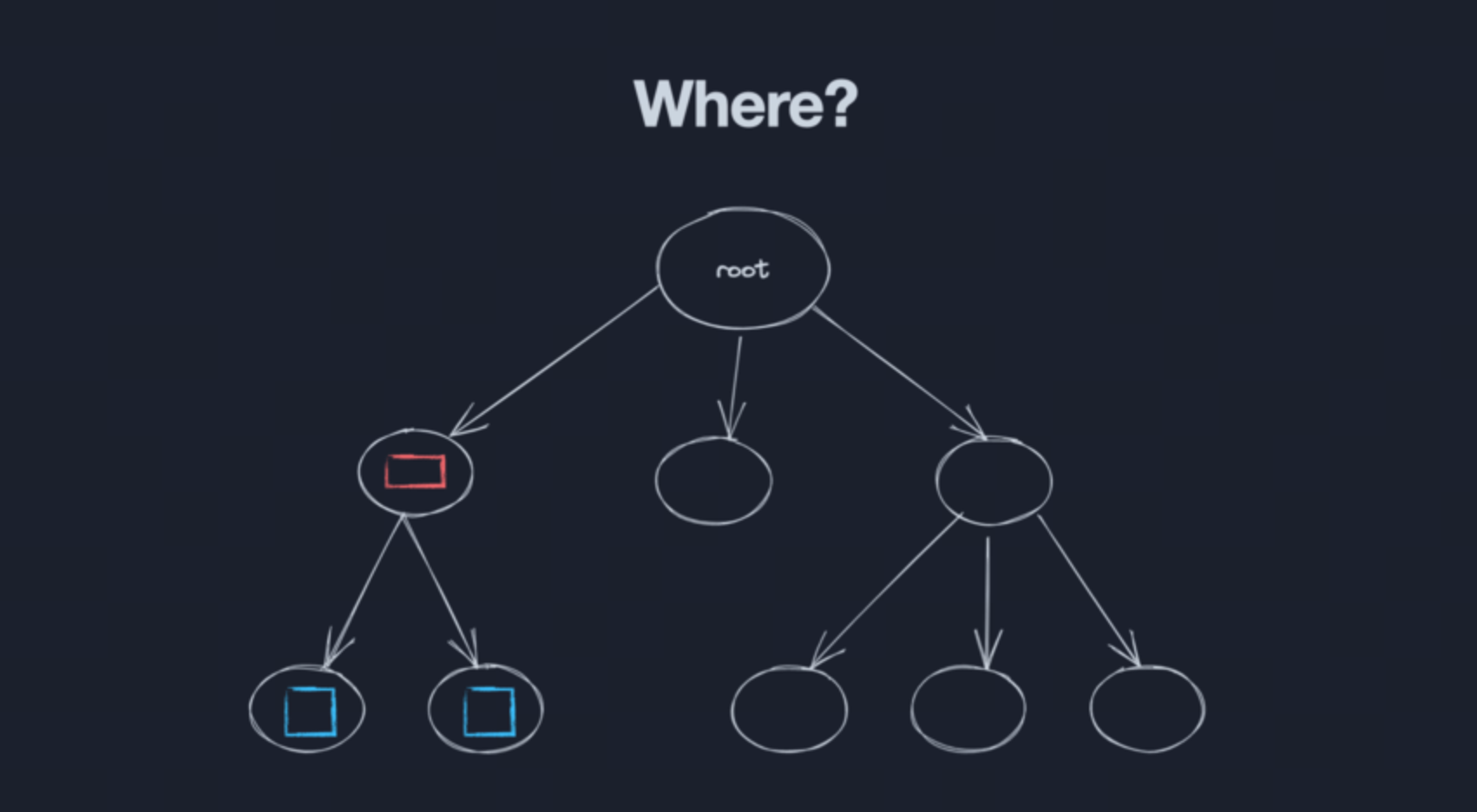
非前端视角
跳出前端视角事情就更简单了,因为上面已经说过异步状态是共享所有权的,我们拥有的只是某个时刻的快照而已
从一致性角度看,快照可以是过时的,但不能是多版本的
可以接受这两个数字是相同但是过时了,但不能接受两个数字不一样
也就是说同一份异步状态不管多少地方在用,都需要一种方式使其保持一致,答案很明显也是全局状态管理
异步状态管理
数据获取很简单,异步状态管理不是
所以接下来使用 redux-thunk 来封装实现异步状态管理,看下为什么说异步状态会有如上的挑战,以及如何解决
结构定义
下面应该是使用 redux-thunk 请求异步数据的最简代码,有两点值得注意:
- 把所有的异步请求数据都放在一个命名空间下:
ASM,与其他同步状态区分开 - 参数传入每一个异步数据的具体要存的键
queryKey和具体要执行的请求函数queryFn- 这点区别于现有的使用方式,目前大家应该是每个
modal单独写一遍请求逻辑,key 随modal的定义在对应的文件中
- 这点区别于现有的使用方式,目前大家应该是每个
export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
return queryFn(props).then((data) =>
dispatch({ ASM: { [queryKey]: { data } } })
)
}TIP
本文所有代码目的均为说明作用
完整的
dispatch应该是dispath({ type, payload }),为了简化代码就都省略了
使用代码如下
const dispatch = useDispatch()
const queryKey = "taskList"
useEffect(() => {
dispatch(
fetchAsyncState({
queryKey,
queryFn: () => fetch("/api/list").then((res) => res.json()),
})
)
}, [])
const { data } = useSelector((state) => state.ASM[queryKey])上面的代码还是太啰嗦了,实际使用中只有 queryKey & queryFn 会变化,其他都是模版代码,所以再封装一个 useQuery
export const useQuery = (props) => {
const dispatch = useDispatch()
useEffect(() => {
dispatch(fetchAsyncState(props))
}, [])
return useSelector((state) => state.ASM[props.queryKey])
}这下用起来舒服多了
const { data } = useQuery({
queryKey: "taskList",
queryFn: () => fetch("/api/list").then((res) => res.json()),
})假如 N 个组件都在用这个数据,我们不想 queryKey 和 queryFn 分散在各组件中,为了统一管理还需要再封一层(数据层),比如放在 service/*.ts
export const useTaskList = () =>
useQuery({
queryKey: "taskList",
queryFn: () => fetch("/api/list").then((res) => res.json()),
})最终组件里(视图层)直接调用
const { data } = useTaskList()这也是最终的代码结构,后面会持续的修改 useQuery 的实现,但业务层要做的只有最后这两步
请求状态管理
异步状态需要等、慢是不可避免的,但人机交互需要及时响应,我们需要从交互上告诉用户:你的操作我受理了,只是现在需要等待
也就是所有视图中发生异步状态的地方,要在视觉上反馈用户
NOTE
有些时候设计是不会出 loading 效果的,但作为前端一定要提出/直接自己加上去
这里就要夸一夸 antd 了,它可能是内置 loading 属性组件最多的库了:
input/select/button/dropdown/table/modal/tree/card...
作为状态管理要做的事情就是把异步过程状态暴露出来,方便视图层渲染:loading/error/success
回到代码实现,这一步是很简单的,而且相信大家自己一定也都写过:请求过程中使用 status 记录状态
export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
return queryFn(props)
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
.catch((error) =>
dispatch({ ASM: { [queryKey]: { status: "error", error } } })
)
}在 useQuery 中派生出具体的变量方便外部使用:
export const useQuery = (props) => {
// ...
const state = useSelector((state) => state.ASM[props.queryKey])
return {
...state,
isLoading: state.status === "loading",
isError: state.status === "error",
isSuccess: state.status === "success",
}
}TIP
为什么不直接在
fetchAsyncState写isLoading/isError/isSuccess呢?
会有很多重复的代码
dispatch({
ASM: { [queryKey]: { isLoading: true, isError: false, isSuccess: false } },
})
return queryFn(props)
.then((data) =>
dispatch({
ASM: {
[queryKey]: { isLoading: false, isError: false, isSuccess: true, data },
},
})
)
.catch((error) =>
dispatch({
ASM: {
[queryKey]: {
isLoading: false,
isError: true,
isSuccess: false,
error,
},
},
})
)缓存管理
这可能是异步状态管理与同步状态管理最大的差异点了
IMPORTANT
要聊缓存,必须先要明确
queryKey的含义,这很重要
queryKey: "taskList" 的问题
如果大家在用同步状态管理异步数据,这应该就是正在使用的方式了,我们用一个 key 去承载一个接口返回的数据
TIP
这有什么问题吗,有遇到过 BUG 吗?
列表场景

TIP
/api/list?page=1和/api/list?page=2和/api/list?name=s算是同一种状态吗?
queryKey: "taskList" 是它们的唯一标识吗?
page=1的数据渲染在了第二页里,算 BUG 吗?- 同时渲染了两个表格
type=1|2,对其中一个翻页,结果两个同时进行了loading和结果更新,算 BUG 吗? - ...
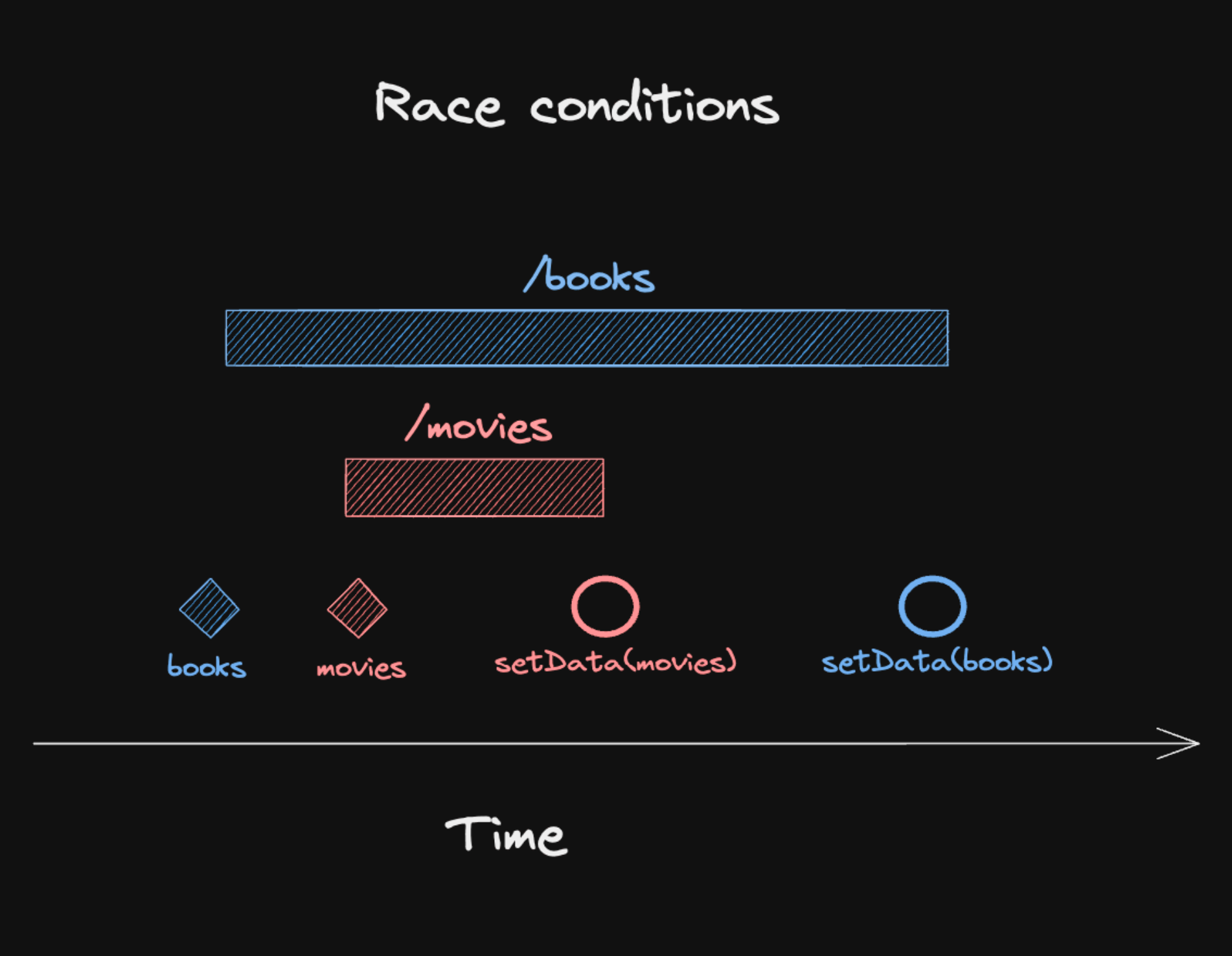
数据竞争:网络请求是没有时序性保证的,先发的请求不一定是先响应的)
这些问题大家多少应该都碰到过,解决方案也有很多,比如:
- 丢弃请求
- 阻塞 UI
- 拆
key - ...
本质是什么?
/api/list?page=1 和 /api/list?page=2 和 /api/list?name=s 根本就不是同一种状态,但在代码开发上却用一个字段承接了 N 种不同的数据
把 N 种状态抽象成了 1 种,抽象的代价就是会遇到各种问题
换句话说,如果不做抽象,就不会有这些问题
数据缓存
还是列表场景,操作路径:
- 分页:
?page=1 -> ?page=2 -> ?page=1(往返翻页) - 搜索:
?page=1 -> ?page=1&s="React" -> ?page=1(搜索后清空)
TIP
Q:频繁重复的获取
page=1的数据,是否有必要?
可能的回答:
要看具体场景,看对数据实时性的要求;还要看请求数据的代价(请求耗时)
TIP
但使用抽象
key的方式,其实是没有选择的因为每次请求成功后,之前的数据就已经被丢弃了,下次只能重新请求获取数据
SWR
而且针对这个问题还有更好的回答:SWR: stale-while-revalidate
TIP
这里的 SWR 指的是 HTTP SWR 概念
后面所说的 useSWR 指 用于数据请求的 React Hooks 库 – SWR 的具体实现
SWR 是指在请求数据时,如果之前已经有缓存了
- 缓存没有过时,直接返回缓存
- 缓存已经过时,仍然返回缓存,同时在后台重新获取数据并更新缓存
原则是「有」总比「空」强(体验好),就算数据是过时的,也比没有数据强(更何况会在几百毫秒内(可能的)新数据就会到来
key 结论
所以不管是从代码开发考虑,还是从数据缓存考虑
都应该具象 queryKey,保证每一个 key 对应一份数据
具体来说就是对于 get 请求,我们应该把 url + [query] + [body] 作为 queryKey,这样就可以标识唯一的数据源了
const queryKey = ["/api/list", { page: 1, name: "s" } /* something... */]实现 SWR
解决 key 的问题
key 序列化
现在的 key 变成了一个非基本类型,不能直接用作对象的 key,所以需要序列化(stringify)操作
也不能用 Map,因为每次 rerender 引用都会变
多数情况 key 的组成都是传给后端的,所以可以直接用 JSON.stringify 来序列化(React Query)
/**
* Hashes the value into a stable hash.
*/
export function hashKey(queryKey: QueryKey | MutationKey): string {
return JSON.stringify(queryKey, (_, val) =>
isPlainObject(val)
? Object.keys(val)
.sort()
.reduce((result, key) => ({ ...result, [key]: val[key] }), {} as any)
: val
)
}键值对的顺序不同,序列化后的字符串也是不同的(但含义相同),所以需要排序
JSON.stringify({ a: 1, b: 1 })
// '{"a":1,"b":1}'
JSON.stringify({ b: 1, a: 1 })
// '{"b":1,"a":1}'也可以直接使用 stable-hash 库(useSWR),它可以稳定序列化任意类型的值(Function/RegExp/BigInt/Symbol..),包括循环引用(JSON.stringify 会直接报错)
// https://github.com/shuding/stable-hash#readme
import hash from "stable-hash"
const foo = []
foo.push(foo)
hash({ a: { b: 2n, c: () => {}, d: [/1/g, Symbol(), foo] } })
// #a:#d:@/1/g,Symbol(),@4~,,,c:5~,b:2,,应用到代码中就是存 key 的时候调用一下 hash 函数:
export const fetchAsyncState = (props) => (dispatch) => {
// ...
payload: { ASM: { [hash(queryKey)]: { /* */ } } },
// ...
}key 变化时请求数据
利用 useEffect 可以轻易做到(记得 hash key)
export const useQuery = (props) => {
// ...
useEffect(() => {
// ...
}, [hash(props.queryKey)])
// ...
}React Query/useSWR 都建议使用这种方式监听 key 变化以重新发起请求,而不是手动调用请求函数
有人希望 useQuery 提供一个类似 manualFetch 的返回值,以在事件发生的时候手动传入参数进行请求:
// ❌ 示例:不存在这样的 API,也不建议
const { manualFetch } = useQuery({
key: {
/**/
},
})
const onPageChange = (page) => {
manualFetch({ page })
}单从封装的角度是不能提供手动函数的
-
后面会讲自动缓存更新,如果使用手动查询更改
key,会产生更多的心智负担useQuery里已经传入了一个key(外部状态manualFetch也会传入key(内部状态- 这是两个数据源,且有优先级之分,且优先级更高的
manualFetch数据源的状态被封装在了useQuery内部
官网建议手动请求?
React 官网 Sending a POST request - You Might Not Need an Effect 中:
当您选择是否将某些逻辑放入事件处理程序或 useEffect 中时,您需要回答的主要问题是从用户的角度来看它是什么样的逻辑
- 如果此逻辑是由特定交互引起的,请将其保留在事件处理程序中
- 如果是由于用户看到屏幕上的组件引起的,请将其保留在 useEffect 中
论点:尽可能让事情发生在它产生的地方
内存野指针难以排查,因为它们往往是由一系列复杂的交互和操作引起的,而且出现问题的症状可能不会立即显现,或者不在引起问题的实际代码位置出现
但实际上这只是针对 变更 操作,对于 查询 操作官方紧跟着就给出了说法:
Fetching data - You Might Not Need an Effect
您不需要将此 获取 移至事件处理程序
这可能看起来与前面的示例相矛盾,在前面的示例中您需要将逻辑放入事件处理程序中!
但是,请考虑到 input 事件并不是获取数据的主要原因,搜索输入通常是从 URL 预先填充的,用户可以在不输入的情况下导航后退和前进。
page 和 query 来自哪里并不重要。虽然此组件可见,但您希望使 results 与当前 page 和 query 的网络数据保持同步。这就是为什么它是一个 useEffect
key可能不是单一来源(url)- 查询操作是幂等的,可以并行、重复和取消的,只要最终的数据和参数一一对应即可
- 变更操作相反,需要阻塞 UI 操作
这也是为什么 React Query/useSWR 都给我们提供了用以变更的方法 useMutation/useSWRMutation,以使得查询和变更分开
完善 SWR
key 的问题解决之后,其实已经实现了 SWR 的功能,回顾下目前的代码
export const fetchAsyncState = (props) => (dispatch) => {
const { queryKey, queryFn } = props
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
return queryFn(props)
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
.catch((error) =>
dispatch({ ASM: { [queryKey]: { status: "error", error } } })
)
}
export const useQuery = (props) => {
const hashKey = hash(props.queryKey)
useEffect(() => {
dispatch(fetchAsyncState({ ...props, queryKey: hashKey }))
}, [hashKey])
const state = useSelector((state) => state.ASM[hashKey])
// ...
}再看分页场景:?page=1 -> ?page=2 -> ?page=1
- 首先,每个
key都被单独保存了一份数据 - 我们并没有做任何清理
data的动作,所以如果data之前已经有值了,那么useSelector很自然的就会获取到已有的值 - 同时新的请求依然会被发送出去,然后更新
data
缓存时长
回顾下 SWR 的定义:
SWR是指在请求数据时,如果之前已经有缓存了
- 缓存没有过时,直接返回缓存
- 缓存已经过时,仍然返回缓存,同时在后台重新获取数据并更新缓存
但目前的代码里根本就没有过不过时的概念,不会出现「缓存没有过时」的情况
我们可以加入一个 staleTime 的配置,来控制异步数据的过期时间,如果数据还是新鲜的,就不会发起请求,直接返回缓存
staleTime:数据从新鲜(fresh)转变为陈旧(stale)的持续时间只要查询是新鲜的,数据将始终只从缓存中读取 - 不会发生网络请求!
如果查询已过时(默认情况下是:
0立即过时),您仍将从缓存中获取数据,但在某些条件下可能会发生后台重新获取(如果过时的时候并没有任何使用此数据的组件挂载,则不会发起请求)-- React Query
代码中,当数据请求成功后,记录一个时间
export const fetchAsyncState = (props) => (dispatch) => {
// ...
dispatch({ ASM: { [queryKey]: { status: "success", data, dataUpdatedAt: Date.now() } } }),
//...
};触发请求时,判断数据是否过期
export const useQuery = (props) => {
// ...
const staleTime = props.options?.staleTime || 0
const state = useSelector((state) => state.ASM[hashKey])
useEffect(() => {
if (state.dataUpdatedAt + staleTime < Date.now()) return
dispatch(fetchAsyncState({ ...props, queryKey: hashKey }))
}, [hashKey])
// ...
}默认情况下 staleTime 为 0,即立即过时
从库的设计角度,0 是最安全的
让使用者根据自己的应用场景去思考决定数据的新鲜度。即使不思考,程序也不会因此出错
如果希望数据在程序的运行期间都不过期,可以设置 staleTime: Infinity
比如登录用户的信息(
/user、/me...
useSWR
useSWR 中并没有 staleTime 的概念,只有 revalidateIfStale & dedupingInterval
revalidateIfStale = true: 即使存在陈旧数据,也自动重新验证
revalidateIfStale: true === staleTime: 0revalidateIfStale: false === staleTime: Infinity
dedupingInterval = 2000: 删除一段时间内相同 key 的重复请求
- 从行为上看似乎类似于
staleTime
其实 HTTP SWR 中也是有 staleTime 的概念的
Cache-Control: max-age=604800, stale-while-revalidate=86400后面会讲到请求去重、自动更新和手动缓存失效
staleTime 的概念可以轻松的与这些概念结合,没有什么心智负担
staleTime = Infinity的情况下,手动缓存失效,会重新发起请求吗?
revalidateIfStale & dedupingInterval 就不是这样了
dedupingInterval = Infinity的情况下,手动缓存失效,会重新发起请求吗?
dedupingInterval配置的主要作用是防止在指定时间间隔内重复发送相同的请求。它不会影响使用mutate函数来更新数据或者触发重新请求
数据更新
自动更新(Smart refetches)
所有的异步状态管理都会提供这些能力,使用得当可以让用户体验上升一个层级
React Query 选择了一些触发重新获取的策略点
这些点似乎是一个很好的指标,可以表达:「是的,现在是获取一些数据的好时机」
refetchOnMount
每当安装调用
useQuery的新组件时,React Query 都会进行重新验证
目前的实现就是这样
refetchOnWindowFocus
每当您聚焦浏览器选项卡时,就会重新获取
这是我最喜欢进行重新验证的时间点
但它经常被误解,在开发过程中,我们经常切换浏览器选项卡,因此我们可能会认为这「太多」
然而在生产中,它很可能表明在选项卡中打开我们的应用程序的用户现在从检查邮件或阅读 Twitter 回来
在这种情况下,向他们展示最新的更新是非常有意义的
功能的代码实现就是监听 focus visibilitychange 重新发起请求
目前只会在 queryKey 变化时,才会重新发起请求,现在我们需要加入另一个状态: isInvalidated,true 表示需要重新请求
为什么要通过加一个状态来实现呢?手动更新中会看到它的巧妙之处
export const useQuery = (props) => {
// ...
const state = useSelector((state) => state.ASM[hashKey]);
useEffect(() => {
const fn = () => visible && dispatch({ ASM: { [hashKey]: { /**/, isInvalidated: true } } })
window.addEventListener('visibilitychange', fn)
return () => window.removeEventListener('visibilitychange', fn)
}, [hashKey])
useEffect(() => {
if (!state.isInvalidated && state.dataUpdatedAt + staleTime < Date.now()) return;
// dispatch(fetchAsyncState(/**/));
}, [hashKey, state.isInvalidated]);
};
// 请求成功后要重置状态
export const fetchAsyncState = (props) => (dispatch) => {
// ...
dispatch({ ASM: { [queryKey]: { status: "success", /**/, isInvalidated: false } } }),
// ...
};refetchOnReconnect
如果您失去网络连接并重新获得它,这也是重新验证您在屏幕上看到的内容的一个很好的指示
同上,监听 online/offline,不再赘述
refetchInterval
定时轮询,窗口不可见时会停止轮询
refetchIntervalInBackground:窗口不可见时依然轮询
useSWR:refreshInterval + refreshWhenHidden
怎么使用得当?
- 编辑表单不要使用(或者谨慎使用
- 数据消失
!==数据删除/无效 的场景不要使用(eg. 推荐流 - 使用强/弱
loading(后面说
手动更新
进行 变更 操作之后,明确知道数据源发生变化了,数据已经过时了
Q: 需要重新发起请求(吗?)
A: 取决于当前页面中有没有组件在使用这个数据源
大家现在是怎么做的,在哪做的(视图层 or 数据层)?或者说是在组件里,还是在 redux 里
应该都是在组件里:
const onClick = () => {
dispatch({ type: "task/delete" }).then(() => {
dispatch({ type: "task/getList", payload: searchParams })
})
}如果放在 redux 里会有以下问题
- 抽象
key的问题,重新请求参数应该传什么?(要把参数也记到redux中) dispatch({type: 'task/getList'})会直接触发网络请求,无法判断是否有组件正在使用数据
switch (type) {
case "task/delete":
fetch("/api/delete").then(() => dispatch({ type: "task/getList" }))
}就是说因为代码原因,无法(不能简单的)把它抽象到数据层中,所以不得不在视图层做
期望数据层的事尽可能放在 uu ju c g 数据层做,而不是散落在视图里
在我们目前的实现中,可以轻松的解决这个问题,把逻辑都放在数据层中
只需要提供如下代码:
export const invalidateQueries = (key) => {
const ASM = useSelector((state) => state.ASM);
Object.keys(ASM).forEach((hashKey) => {
const { queryKey } = ASM[hashKey]
// 部分匹配
if (partialMatchKey(queryKey, key)) {
dispatch({ ASM: { [key]: { /**/, isInvalidated: true } } }),
}
})
}
function partialMatchKey(a: any, b: any): boolean {
if (a === b) return true
if (typeof a !== typeof b) return false
if (a && b && typeof a === 'object' && typeof b === 'object') {
return !Object.keys(b).some((key) => !partialMatchKey(a[key], b[key]))
}
return false
}- 原始的
queryKey是会被存下来的(为了避免干扰前面没写 - 这里只实现了部分匹配,因为是最常用的。真正的 invalidateQueries 可以传入
filters精确控制具体的失效逻辑
业务代码中如下使用:
export const useDeleteTask = () => {
return useMutation({
mutationFn: () => fetch("/api/delete"),
onSuccess() {
invalidateQueries(["/api/list"])
},
})
}为什么它有效?
这就是增加一个
isInvalidated的巧妙之处
使用了 useEffect 天然的订阅机制:通过 useEffect 监听了状态的变化发送请求
如果没有任何相关的 useEffect 存在,单纯的修改状态是没有意义的,什么都不会发生
TanStack Query 被设计的不局限于框架,所以抽象了这一部分(
observer)
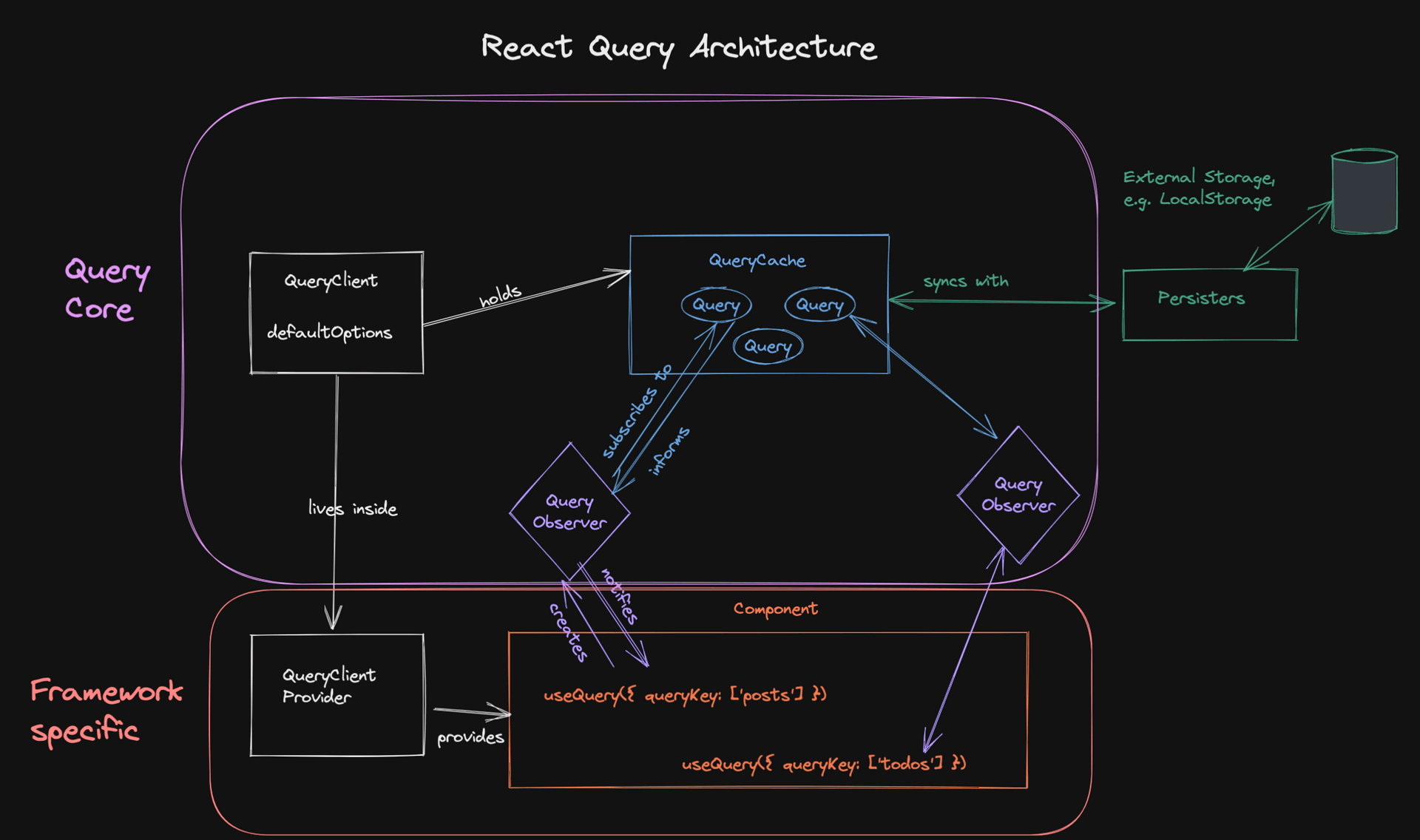
为什么部分匹配就可以了?
实际的业务场景中,很少在页面上同时存在接口路径相同,参数不同的视图(eg. /api/list?type=1、/api/list?type=2)
基于这样的提前:
invalidateQueries(['/api/list'])效果等同于invalidateQueries(['/api/list', {page: 1}])invalidateQueries(['/api/detail'])效果等同于invalidateQueries(['/api/detail', {id: 1}])
而且如果真遇到这种场景,你就把参数传进去呗
手动设置缓存数据
有些后端接口实现中,会在 post/patch 的接口响应里就把最新的数据返回过来,而不用再去发起 get 请求
针对这种场景可以提供 setQueryData 手动更新缓存数据
export const setQueryData = (key, data) => {
dispatch({ ASM: { [key]: { data } } }),
}业务使用如下:
export const useEditTask = () => {
return useMutation({
mutationFn: (params) =>
fetch(`/api/task${params.id}`, { method: "PATCH" }).then((data) => {
setQueryData(["/api/task", { id: params.id }], data)
}),
})
}useSWR 中
mutate(key)等同于invalidateQueries(默认精确匹配,可以传入函数来实现部分匹配mutate(key, data, options)等同于setQueryData
内存和垃圾回收
事情都是两面的,抽象和具象各有优劣
把每一个 key 的数据都存下来,体验好了,内存也上去了
抽象
key是不需要考虑GC的,因为每次请求完,就已经把旧数据释放了,内存中每个抽象key只有一份数据就算用户把所有的页面都点一遍,也只会有代码中
modal数量的数据存在内存中而已
直接看 React Query 是如何解决的
gcTime:从缓存中删除非活动查询之前的持续时间,默认为 5 分钟一旦没有注册观察者,即当使用该查询的所有组件都已卸载时,查询就会转换为非活动状态(
inactive)
如果一份数据已经没有任何组件在使用了,gcTime 后回收它
频繁触发请求的场景可以设置的短一点,比如搜索场景
代码实现上,就是订阅模式配合定时器
依然是利用 useEffect 的特性,配合全局状态管理实现:「是否还在组件在使用数据」
export const useQuery = (props) => {
// ...
useEffect(() => {
dispatch({ type: "gc/add", payload: hashKey })
return () => dispatch({ type: "gc/remove", payload: hashKey })
}, [hashKey])
// ...
}redux 中:
case 'gc/add':
const {count = 0, timer} = state.GC[hashKey] || {}
clearTimeout(timer)
return { GC: { [hashKey]: { count: count + 1 } } }
case 'gc/remove': {
const count = state.GC[hashKey] - 1
let timer
if (count === 0 && state.ASM[hashKey]) {
timer = setTimeout(() => {
state.ASM[hashKey] = null
}, crime)
}
return { GC: { [hashKey]: { count, timer } } }
}useSWR 中并没有提供清理缓存的相关配置,但是它允许你完全 自定义缓存行为,所以可以自行实现相关功能
请求合并(去重)
目前的同步全局状态管理中,如果大家要取一个全局的数据(比如 userInfo),是用哪种方式取的?
- 找一个足够高的父组件,使用
useSelector取到后,利用props向下不同的透传(props drilling) - 直接在使用的地方
useSelector取
我觉得在问废话,当时是 2 啊(不会真的有人用 1 吧 😱
我们知道 useQuery 的实现其实也只是一个有副作用的 useSelector 而已
export const useQuery = (props) => {
// ...
const state = useSelector(/**/)
useEffect(/**/)
// ...
}我们希望对于使用者(视图层)来说,就把它当成 useSelector,只管取数据、用数据就好了
- 不要去管数据从哪来的
- 不要去管数据有没有过时
- 不要去管数据为什么会更新
- 不要去管会不会重复请求
- ...
这些都是数据层的事情,视图层管好渲染就可以了
当然这是理想状态,只能尽可能去做
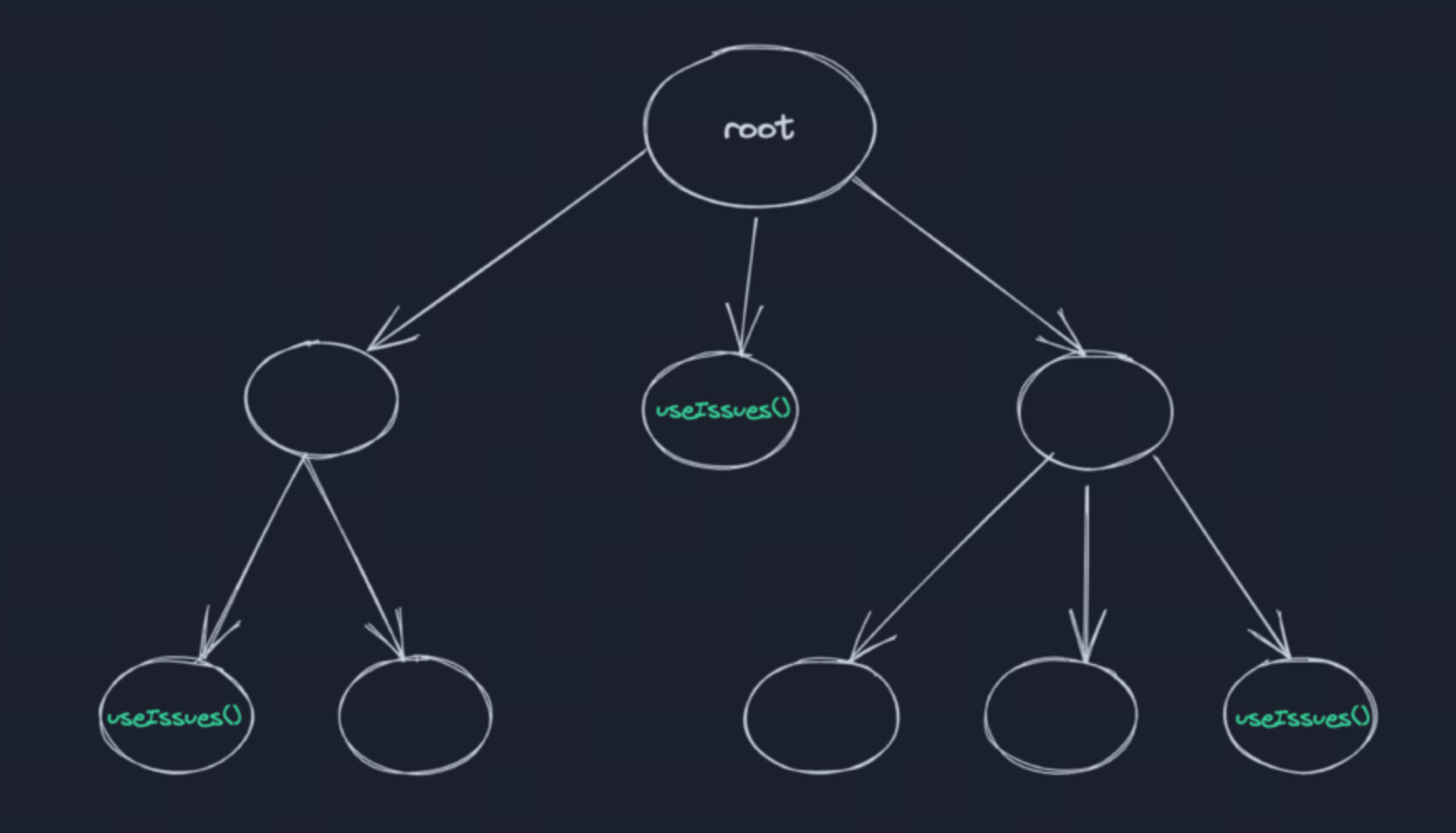
目前的实现如果多个组件同时挂载,是会同时发出多个请求的
只需要加入 loading 态的判断即可完成去重
export const fetchAsyncState = (props) => (dispatch, getState) => {
const { status } = getState().ASM[queryKey] || {}
if (status === "loading") return
dispatch({ ASM: { [queryKey]: { status: "loading" } } })
// ...
}TIP
抽象
key这样写就会有问题,因为可能会有不同参数的请求进来
上面的代码控制了接口 loading 过程中的重复请求(取决于接口的速度,也许是几百毫秒)
对于同步的组件树挂载,这已经足够了(面试题:useEffect 的调用时机和顺序
但如果遇到异步组件(lazy load),就还有可能发生重复请求,那应该怎么办呢?
staleTime 是你的好朋友
staleTime也没有「正确」值。在许多情况下,默认设置(0)效果非常好就个人而言,我喜欢将其设置为至少 20 秒,以便在该时间范围内删除重复请求,但这完全取决于您
-- React Query
丢弃/取消请求
有些场景请求的数据已经不可能再被使用了,此时需要忽略/丢弃/取消请求的结果
- 快速的翻页(只有最后停留的页面数据才是有用的
- 没有搜索按钮,只靠节流且没有兼容中文输入法的搜索框(最后上屏的中文才是要搜的
- 导航栏路由快速切换(组件都已经卸载了,还请求数据干嘛
相信这些问题大家多少也遇到过
- 抽象
key:前两种情况必须要去解决,不然就会有 BUG(弱网必现 - 具象
key:可以不解决,是不会有 BUG 的。但考虑到缓存、GC 的原因,最好还是解决一下
可以用 AbortController 优雅的实现相关逻辑
- 可以直接传递给
fetch,以实现请求取消( promise reject - 也可以在自定义逻辑中访问
aborted属性实现丢弃逻辑
const ac = new AbortController()
console.log(ac.signal.aborted) // false
ac.abort()
console.log(ac.signal.aborted) // true具体到代码中,在每次请求时创建一个 AbortController 实例,并将其 signal 传递给实际的执行者:queryFn
export const fetchAsyncState = (props) => (dispatch) => {
// ...
const ac = new AbortController()
dispatch({ ASM: { [queryKey]: { status: "loading", ac } } })
return queryFn({...props, signal: ac.signal })
.then((data) =>
dispatch({ ASM: { [queryKey]: { status: "success", data } } })
)
}
// GC
case 'gc/remove': {
if (count === 0 && state.ASM[hashKey]) {
state.ASM[hashKey]?.ac?.abort()
// timer = setTimeout(() => {
}
}而使用者只需要在 queryFn 中使用 signal 就可以了(绝大多数情况也是直接透传给 fetch
export const useTaskList = () =>
useQuery({
queryKey: "taskList",
queryFn: ({ signal }) =>
fetch("/api/list", { signal }).then((res) => res.json()),
})用户体验
loading
大多数时候,我们(和我们的用户)不喜欢讨厌的加载旋转器。
有时它们是必需的,但我们仍然希望尽可能避免它们
这就是为什么 React Query/SWR 会为我们提供两个 loading 变量:
isLoading: 请求中且没有数据可用isFetching/isValidating: 请求中已有数据可用
为了良好的用户体验,要准备两个 loading 效果
- 强
loading:首次请求时,没有数据可用于渲染 - 弱
loading:数据更新(手动/自动)时,页面中已有数据渲染



配合组件化
错误处理
处理错误是处理异步数据(尤其是数据获取)不可或缺的一部分
我们必须面对现实:并不是所有的请求都会成功,也不是所有的 Promise 都会得到履行
对于初始请求(没有数据),没有什么可以值得讨论的,我们需要展示降级的视图或提示
一般使用全局处理 or 组件封装的方式来解决
对于数据更新的场景,如果你用的是 toast 错误提示,也还好
但如果用的是渲染错误视图的方式,就要多考虑一下了,尤其是自动更新的场景: refetchOnWindowFocus/refetchOnReconnect ,如果此类自动更新获取失败,可能会导致用户体验混乱
比如用户在浏览列表的时候来了个微信消息,等回完消息从微信切回浏览器后,发现列表变成了一个错误提示视图
优先展示错误还是陈旧的数据?这个问题没有明确的答案,取决于具体场景
对于一个库来说,要做的就是「同时将收到的错误和过时的数据返回给用户」(目前的代码实现就是这样)
现在,由你来决定显示什么:
- 显示错误很重要吗?
- 仅显示陈旧数据是否足够?
- 或者同时显示两者?
const { data, error } = useTodos()
// 错误优先
if (error) return "An error has occurred: " + todos.error.message
if (data) return todos.data.map(renderTodo)
// 数据优先
if (data) return todos.data.map(renderTodo)
if (error) return "An error has occurred: " + todos.error.message
// 同时展示
return (
<>
{error && "An error has occurred: " + todos.error.message}
{data && todos.data.map(renderTodo)}
</>
)乐观更新
在合适的场景里又是一个提升体验的大杀器
这种策略的核心思想是在数据实际写入服务器之前,就假设写入操作会成功,并且立即在前端应用中更新数据
这样做的目的是为了提升用户体验,减少等待时间,并给予用户一种快速响应的感觉
目前我们对 变更 操作的处理应该都是阻塞 UI:给用户一个 loading/disable,在此期间无法进行其他操作,直到接口响应(成功/失败
在有业务校验的场景(eg 购物),这是合理的,因为会有很多因素导致失败(余额、商品数量、地址…),有些来自于用户输入,这是无法控制的
但有些场景(eg 聊天、评论),接口的成功/失败只取决于服务可用性,我们知道所有公司都对服务可用性有要求
高可用性指标通常用“几个 9”来表示,即系统在一年中的正常运行时间所占的百分比。例如:
- 99.9%(三个 9):在一年中最多允许 8.76 小时的停机时间。
- 99.99%(四个 9):在一年中最多允许 52.56 分钟的停机时间。
- 99.999%(五个 9):在一年中最多允许 5.26 分钟的停机时间。
既然很多时候(> 99.9%),我们非常确定更新将会完成,为什么还要用户多等待几秒钟,直到从后端获得许可才能在 UI 中显示结果?
乐观更新的想法是在我们将
mutate发送到服务器之前就 伪造 成功,一旦我们收到成功的响应,所要做的就是使缓存失效以获取真实的服务端数据如果请求失败,我们将把 UI 回滚到
mutate之前的状态(并在接下来回退到阻塞模式)
交互流程大概如下,以列表新增为例:
-
用户点击新增按钮后,同时进行以下操作
- 发起请求
- 手动修改列表数据,
unshift新数据 - 关闭新增弹窗
-
请求过程中,列表已经展示了本地数据行,但最好在视觉上提醒用户这不是终态,比如可以:
- 对本地数据行加入弱
loading - 对本地数据行加入半透明效果
opacity: 0.5- 配合一些插入的过渡动画,可以实现无感更新
- 对本地数据行加入弱
-
请求成功,什么都不需要做
-
请求失败,可以做如下操作
- 回滚列表数据,给出
toast错误提示 - 不回滚列表数据,直接给本地数据行加入错误 UI(比如红色背景和错误原因)
- 回滚列表数据,给出
一旦发生乐观更新失败的场景,就关闭乐观更新模式,回退到阻塞模式
配合组件化
Via the Cache
React Query 提供了两种乐观更新的方式,先来看标准的:通过修改缓存数据实现
const queryClient = useQueryClient()
useMutation({
mutationFn: updateTodo,
// 每次 mutate 被调用时触发:
onMutate: async (newTodo) => {
// 1. 取消所有正在进行的列表获取请求
// 因为它们会覆盖我们的乐观更新
await queryClient.cancelQueries({ queryKey: ["todos"] })
// 2. 获取目前的数据快照,以便我们可以回滚
const previousTodos = queryClient.getQueryData(["todos"])
// 3. 乐观更新,直接修改数据
// 加入了 isOptimistic 字段,方便视图中的展示判断
queryClient.setQueryData(["todos"], (old) => [
{ isOptimistic: true, ...newTodo },
...old,
])
// 4. 将快照存入 context,以便在失败时回滚
return { previousTodos }
},
// 如果失败,使用 onMutate 返回的 context 回滚
onError: (err, newTodo, context) => {
queryClient.setQueryData(["todos"], context.previousTodos)
},
// 无论成功还是失败,这个函数都会被调用,在此重新获取列表数据
// 成功时获取最新的服务端数据以同步乐观更新的状态
// 失败时获取是因为我们为了防止乐观更新被覆盖,在第一步取消了正在进行中的请求,此时要让它们继续
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ["todos"] })
},
})Via the UI
很取巧但是更简单的方式,不会去修改缓存数据,利用 mutate + query 配合 loading 直接在 UI 层做乐观更新
首先数据层代码是这样的:
useMutation({
mutationFn: updateTodo,
// make sure to _return_ the Promise from the query invalidation
// so that the mutation stays in `pending` state until the refetch is finished
onSettled: async () => {
return queryClient.invalidateQueries({ queryKey: ["todos"] })
},
})看起来好像什么都没有做:我们发起请求,并在完成后触发缓存失效更新数据,这是最常规的写法
诀窍在 onSettled 的 return,它返回了 queryClient.invalidateQueries
我们知道 invalidateQueries 的作用是使缓存失效,但实际上它会返回一个 promise,缓存失效时如果触发了网络请求,promise 会在请求成功之后 resolve
也就是说上面的代码等同于:
return fetch("/api/update", { method: "POST" }).then(() => fetch("/api/todos"))它把 mutate 和 query 链接在了一起,变成了一个 promise 链,当整个链条没有 resolve 时,useMutation 也不会结束
所以视图层我们可以直接访问 isPending 来展示乐观更新的状态
const { isPending, variables } = useMutation()
<ul>
{todoQuery.items.map((todo) => (
<li key={todo.id}>{todo.text}</li>
))}
{isPending && <li style={{ opacity: 0.5 }}>{variables}</li>}
</ul>非常的巧妙,如果请求成功了,isPending 就会变成 false,这样就不会展示乐观更新的数据了,但同时最新的列表数据也已经请求回来并更新在了 UI 上
如果请求失败了,isPending 同样变为 false,相当于自动执行了回滚操作
这是一个取巧且简单的方法,所以有着一些局限性:
- 只能同时存在一个乐观更新的数据,因为
isPending只有一个- 以现在的网络情况多数也够用了,就算支持多数据同时乐观更新,用户操作的速度也很难跟上网络请求的速度
- 无法控制是否回滚数据
- 有些时候我们不想回滚数据,而是在 UI 上给予提示和重试的操作,这种方式是做不到的
渲染依赖优化
考虑如下场景:
const result = useTaskList()
const { isLoading, data } = result我们知道 result 里的数据是会频繁变化的,比如当 isFetching/error/isInvalidated... 变化时
但这个组件只使用了 isLoading & data,如果其他数据的变化导致了 result 变化,进而导致组件重新渲染,这有必要吗?
因为我们只使用了 isLoading & data,所以其他数据的变化并不会导致重新渲染的组件有什么变化,所以这是没有必要的
React Query 通过监听数据的 get,实现了只会在使用的数据变化时,重新渲染组件
目前 redux 的代码,没法简单的实现这个功能,所以就直接看 ReactQuery 的源码吧
trackResult(
result: QueryObserverResult<TData, TError>,
): QueryObserverResult<TData, TError> {
const trackedResult = {} as QueryObserverResult<TData, TError>
// 只监听了第一层
Object.keys(result).forEach((key) => {
Object.defineProperty(trackedResult, key, {
configurable: false,
enumerable: true,
get: () => {
this.#trackedProps.add(key as keyof QueryObserverResult)
return result[key as keyof QueryObserverResult]
},
})
})
return trackedResult
}
const shouldNotifyListeners =() => {
const includedProps = new Set(this.#trackedProps)
return Object.keys(this.#currentResult).some((key) => {
const typedKey = key as keyof QueryObserverResult
const changed = this.#currentResult[typedKey] !== prevResult[typedKey]
// 发生更新并且数据被访问过
return changed && includedProps.has(typedKey)
})
}结构共享优化
每次从后台请求回来的数据,即使数据完全没有变化,引用也全部都是新的了
考虑如下响应,新获取的数据中只 id=1 发生了变化,id=2 数据是没有变的
[
- { "id": 1, "name": "Learn React", "status": "active" },
+ { "id": 1, "name": "Learn React", "status": "done" },
{ "id": 2, "name": "Learn React Query", "status": "todo" }
]React Query 会深度比较数据,并尽可能多地保留以前的状态(引用)
对于上面的响应,id=1 会是一个新的引用,而 id=2 则仍然是之前的引用
虚拟 DOM diff -> 减少 DOM 的操作
数据 diff -> 减少 虚拟 DOM 的操作
More
- 预渲染
- 条件查询(依赖查询)
- 请求失败自动重试
- 无限滚动查询
- 离线缓存
- 服务端渲染
Suspense- ...
还可以接着列,但是没有必要了,详细的可以直接去看对应库的官网
就目前说的这些,已经完全可以说明同步、异步状态管理的不同了
回过头来再看:「数据获取很简单,异步状态管理不是」,也可以说「代码开发很简单,用户体验不是」